Optimizando imágenes para la web
Next nos ofrece una serie de mecanismos para optimizar las imágenes que utilizamos en nuestras aplicaciones web. Pero primero tenemos que preparar esas imágenes. Vamos a ver como hacer ambas cosas en esta entrada

He estado dándole una vuelta a como uso las imágenes en este blog. Hasta el momento el proceso venía resultando bastante traumático. Me dí cuenta de esto en un momento en el que me vi en la tesitura de añadir una nueva imagen y sentí una pereza infinita. Lo cual me llevo a reflexionar:
Bueno, otro no, tendré que hacerlo yo. Pero puedo automatizar con un script la parte tediosa de optimizar las imágenes y no volver a pensar en ello. Los pasos que tenía que hacer hasta ahora cada vez que quería añadir una nueva imagen eran:
-
Convertirla a formato webp, un formato sin pérdida de calidad, que reduce el tamaño de las imágenes considerablemente y que está desarrollando Google precisamente para su uso en webs.
-
Redimensionarla al máximo tamaño que se va a mostrar, en el caso de esta web a 700px de ancho. Con el objetivo de tener la mejor calidad posible mandando la menor cantidad de datos.
-
Finalmente, introducir la ruta de la imagen en el markdown, incluyendo la carpeta y la extensión, que siempre son la misma (images y .webp respectivamente).
Por otro lado, con el aproach actual a parte de frustración vengo echando en falta dos funcionalidades que el component Image de Next nos da gratis:
-
Por un lado, el lazy loading: No descargar la imagen hasta que no este próxima a aparecer en la página a causa del scroll que haga el usuario. Hasta ahora todas las imágenes se cargaban al acceder a la página, generando una carga en el dispositivo y en la red innecesaria.
-
Mientras las imágenes no se han descargado, mostrar una versión de la misma en baja resolución y calidad a modo de placeholder. Esto cumple dos funciones: Por un lado indicar visualmente que la imagen se esta cargando si por circunstancias de la red esta descarga toma el suficiente tiempo como para que el usuario vea el placeholder. Y ocupar el espacio que la imagen final vaya a ocupar, antes de que esta se descargue. De modo que evitamos que el contenido se vea desplazado por esta al descargarse provocando el denominado layout shift
Para esto último vamos a necesitar saber de antemano cual es el tamaño de la imagen y además haber generado el placeholder con antelación. Como vamos a automatizar la gestión de las imágenes, aprovecharemos también para afrontar estas dos tareas con el script que vamos a escribir.
El proceso que venía haciendo hasta ahora
Como he comentado en alguna ocasión, utilizo una maquina Windows con WSL2 corriendo Ubuntu para desarrollar:
WSL es básicamente una máquina virtual altamente integrada en el sistema que permite asimilar un subsistema Linux dentro de un sistema operativo Windows. Gracias a esta tecnología tienes acceso a una terminal en la que puedes instalar y correr cualquier cosa que correría en un Ubuntu, Debian, Arch, etc, pero dentro de tu sistema operativo de Microsoft. Utilizando tu IDE, tu terminal o tu explorador de archivos nativo a traves de túneles que, en la versión actual, son prácticamente imperceptibles para el usuario.
Esta maravilla de la tecnología me permite tener en Windows una experiencia de desarrollo casi 1:1 con la que tengo en un sistema Linux o Mac, pudiendo aprovechar el PC Gaming que principalmente uso para jugar (Única tarea en la que el sistema de microsoft aun es muy superior a OSX, Debian, Ubuntu, etc.) para trabajar en mis proyectos de desarrollo en un entorno idéntico al que uso en el trabajo (terminal Unix).
WSL expone los puertos de los servicios que estés corriendo, asi que puedes correr una aplicación web y visitarla desde tu navegador. Puedes instalar aplicaciones gráficas como GIMP usando snap y utilizarlas desde el escritorio sin problemas. Puedes navegar el sistema de carpetas y gestionar los archivos desde el explorer de Windows. Esto último es importante para el tema que nos ocupa, dado que los archivos estáticos (imágenes) los descargo o las genero desde el sistema anfitrión y necesito copiarlas al subsistema Linux. En primeras versiones de WSL esto era un autentico suplicio. A día de hoy puedes abrir el sistema de archivos de WSL desde el explorador de Windows como si de una partición se tratara y copiar y pegar archivos sin problemas. Incluso arrastrando desde tu navegador a el explorador de archivos de VsCode (Que se conecta al entorno de desarrollo de WSL) puedes copiar archivos.
Volviendo al que era mi proceso hasta ahora, este consistía en:
-
Copiar la imagen que quisiera usar en el blog a la carpeta de imágenes de mi proyecto, en este caso
/public/images. Next expone como archivos estáticos todo lo que pongas en la carpeta/publicpor lo que puedo acceder a las imágenes desde cualquier parte de mi aplicación simplemente referenciando a/images/nombre-de-la-imagen.extension-de-la-imagen. -
Utilizar un conversor a webp para convertir la imagen a ese formato. En mi caso utilizaba cwebp que es la herramienta de Google para convertir imágenes a webp. Desde la terminal:
cwebp nombre-de-la-imagen.extension-de-la-imagen -o nombre-de-la-imagen.webp
- Utilizar la imagen en el Markdown:

Lo cual es un proceso que me producía pereza cada vez que tenía que añadir una imagen. Copiar un archivo, ejecutar un comando y escribir una ruta completa puede parecer poca cosa. Pero cuando estás escribiendo un post, hacerlo cada pocos minutos te rompe totalmente el ritmo y acabas o bien no queriendo añadir imágenes, o no queriendo escribir más directamente.
Por otro lado, está el tema del tamaño de las imágenes. Next se encarga de sobredimensionarlas al vuelo si usas el componente Image, pero para ello tienes que especificar el tamaño final de la imagen con un width y un height.
Si no lo haces, puedes usar la propiedad fill y especificar el tamaño en el contenedor con CSS. En mi caso me encontraba con la problemática de que tengo algunas imágenes que llenan la columna (700px de ancho o mas) y otras que no lo hacen, en cuyo caso quería que quedaran centradas. Esto último no se puede hacer con fill ya que el contenedor no se dimensiona en función de la imagén, sino lo contrario. Para más INRI, pierdes la optimización que hace Next de las imágenes puesto que no sabe a qué tamaño debe dimensionarlas.
Total, que en un principio opté por no calentarme la cabeza y usar el elemento img nativo de HTML, ya que este descarga la imagen y por defecto la muestra a su resolución nativa en el navegador. Pero esto me causaba un tercer problema: El espacio no se ocupa hasta que la imagen se descarga, por lo que el layout de la página se va modificando conforme se completa la transferencia de los assets: básicamente, el contenido de la página da "saltos" conforme las imágenes se descargan y esto queda horroroso. Y este efecto es efectivamente el famoso cumulative layout shift
Haber convivido con esta experiencia de desarrollo tan nefasta con un resultado final tan pobre durante tantos meses me ha terminado armando de valor para ponerme el mandil de scripter y arreglar la problemática de las imágenes en este blog de una vez por todas.
El script optimizador
Vamos a usar zsh para crear este script. Nos va a permitir navegar nuestro sistema de archivos y usar aplicaciones de terminal para automatizar tareas. Podríamos optar por otro lenguaje y entorno de ejecución, por ejemplo Typescript en Node. Pero me parece interesante practicar con la terminal, dado que siempre vas a tener shell disponible en un sistema Linux y quien sabe cuando vas a tener que conectarte con ssh a un contenedor docker para automatizar una tarea. Así que vamos a hacer el esfuerzo y a aprender un par de cosas con este post. Punto por punto:
Copiar las imágenes a la máquina Linux
Esto obviamente no lo podemos automátizar, simplemente es arrastrar y soltar la imagen que quiera. Pero hay una pequeña molestia que si que nos podemos quitar. Al copiar y pegar un archivo de Windows al subsistema Linux, este último crea un archivo :Zone.Identifier para almacenar meta información. ¿Cual? Por ejemplo:
imagen:Zone.Identifier [ZoneTransfer] ZoneId=3 ReferrerUrl=https://photos.google.com/ HostUrl=about:internet
¿Por qué? No lo sé ¿Se puede evitar? No he encontrado como. Así que lo que me tocaba hacer era borrar ese archivo cada vez que copiaba una nueva imagen al repositorio. Vamos a automatizar este proceso en el script:
public/images/process-images.sh #!/bin/sh rm -f "$(dirname "$0")"/*.Identifier
#!/bin/sh indica al sistema cómo debe ejecutar este archivo. Esto es muy interesante ya que podemos, por ejemplo, copiar el script a la carpeta usr/bin y usarlo en cualquier lugar de nuestro sistema simplemente invocando su nombre. Es una manera genial de generar pequeñas aplicaciones para personalizar tu sistema.
rm -f fuerza la eliminación de archivos, "$(dirname "$0")" hace referencia a la carpeta donde se encuentra el script e *.Identifier captura todos los archivos que terminen en .Identifier. Con esto ya nos hemos librado de esos molestos y no solicitados metadatos.
Transformar las imágenes a webp
Lo normal es que las imágenes que copio, dependiendo del origen, sean jpg o png. Por ello necesito analizar la carpeta en busca de todos los archivos que no sean yá .webp para procesarlos:
public/images/process-images.sh ... for file in $(find "$(dirname "$0")" -type f ! -name "*.webp" ! -name "*.sh") do cwebp -q 80 "$file" -o "${file%.*}.webp" rm "$file" done
El bucle for recorre todos los archivos capturados por find "$(dirname "$0")" -type f ! -name "*.webp" ! -name "*.sh":
-
find "$(dirname "$0")"busca en la carpeta donde se encuentra el script. -
-type fcaptura solo archivos. -
! -name "*.webp"excluye los archivos que terminen en.webp, así no procesaremos los que ya estén en ese formato. -
! -name "*.sh"excluye el propio script, ya que obviamente no es una imagen que quiera convertir.
Una vez que tenemos como valor de $file la ruta de la imagen, vamos a convertirla a webp con cwebp -q 80 "$file" -o "${file%.*}.webp".
-
cwebpes el comando que convierte las imágenes a webp. En Ubuntu puedes instalarlo consudo apt install webp. Si utilizas otra distribución o sistema operativo, puedes buscar como hacerlo, suele ser muy sencillo. -
-q 80es la calidad de la imagen. -
"$file"es la referencia a la ruta de la imagen que queremos convertir, que obtuvimos en el buclefor. -
-o "${file%.*}.webp"es la ruta de salida de la imagen (-ode--output).${file%.*}es una forma de obtener el nombre del archivo sin la extensión. Por ejemplo, si$filees/ruta/a/imagen.jpg,${file%.*}será/ruta/a/imagen, a la cual añadimos.webppara obtener la ruta de salida.
Finalmente, eliminamos la imagen original con rm "$file", ya que una vez transformada en webp no necesitamos conservarla.
Redimendionar las imágenes
Lo siguiente es hacer un segundo bucle, ahora ya sobre los archivos .webp que hemos generado, y verificar si queremos redimensionarlos. En esta web, en escritorio, el ancho máximo al que mostramos las imágenes es de 700px. Para llevar a cabo este cometido, voy a usar la suite de herramientas de ImageMagick:
public/images/process-images.sh for file in "$(dirname "$0")"/*.webp do width=$(identify -format "%w" "${file%.*}.webp") # If the width is larger than 700px, resize the image if [ $width -gt 700 ] then mogrify -resize 700x "${file%.*}.webp" fi
-
for file in "$(dirname "$0")"/*.webpes similar al bucle anterior, pero ahora capturamos solo los archivos.webpque hemos generado anteriormente y, ademas, al no usarfindno recorreremos ninguna carpeta interna (Esto es importante dado que posteriormente vamos a crear una carpeta para placeholders y no querremos recorrer su contenido). -
con
width=$(identify -format "%w" "${file%.*}.webp")obtenemos el ancho de la imagen utilizando la utilidadidentifyde ImageMagick. Comparandoon-format "%w"le decimos que lo que queremos es el ancho, y con"${file%.*}.webp"indicamos la ruta de la imagen. Guardamos el resultado una variable$width. -
if [ $width -gt 700 ]comprobamos si el ancho de la imagen es mayor a 700px.$widthes la variable que definimos anteriormente, con el ancho de la imagen.-gtes un operador de comparación que significa "mayor que". -
Si se da el caso de que la imagen es mayor a 700px, redimensionamos la imagen con
mogrify -resize 700x "${file%.*}.webp".mogrifyes otra utilidad de ImageMagick que permite modificar imágenes. Con-resize 700xle decimos que queremos redimensionar la imagen a un ancho de 700px, el alto lo dejamos implicito y se mantendra la misma relación de aspecto. Y con"${file%.*}.webp"le indicamos la ruta de la imagen.
Y con esas pocas lineas, hemos redimensionado todas las imágenes que superen los 700px de ancho. Las que no lo hicieran, no se han tocado.
Generar los placeholders
A continuación generaremos los placeholders. Estos van a ser versiones de poca resolución y poca calidad que vamos a utilizar para mostrar mientras se descargan las imágenes finales. Tenemos que crear imágenes que recuerden a las finales, pero que ocupen unos poco bytes, para que podamos cargarlas casi instantaneamente incluso en condiciones de red poco favorables:
public/images/process-images.sh base=$(basename "$file") placeholderPath=$(dirname "$0")/placeholder/${base} if [ ! -f "$placeholderPath" ]; then convert "${file%.*}.webp" -blur 0x8 -quality 10 -resize 10x "$placeholderPath" fi
-
Con
base=$(basename "$file")obtenemos el nombre del archivo sin la ruta usandobasenamey lo guardamos en la variable$base. -
placeholderPath=$(dirname "$0")/placeholder/${base}es la ruta donde vamos a guardar el placeholder.$(dirname "$0")es la carpeta donde se encuentra el script,/placeholder/es una carpeta que tenemos que crear dentro de la carpetaimagesy$basees el nombre del archivo que definimos antes. -
if [ ! -f "$placeholderPath" ]; thencomprobamos si el placeholder no existe. Con esto evitamos estar creando constantemente los mismos placeholders. Solo lo haremos con aquellos que nos falten. Esto es lo mismo que hacíamos para redimensionar las imagenes a 700px de ancho. -
convert "${file%.*}.webp" -blur 0x8 -quality 10 -resize 10x "$placeholderPath"es la orden que genera el placeholder.convertes otra utilidad de ImageMagick que permite convertir imagenes. La diferencia conmogrifyes que este modifica el original, mientras queconvertcrea una copia."${file%.*}.webp"es la ruta de la imagen original,-blur 0x8desenfoca la imagen en un area de 8 pixeles,-quality 10indica una calidad baja (10 sobre 100),-resize 10xla redimensiona a 10px de ancho y$placeholderPathes la ruta de salida que definimos antes.
Y con solo esa linea, hemos creado los placeholders.
Guardar las dimensiones de las imagenes
Una vez tenemos la imagen redimensionada, necesito almacenar su tamaño para poder indicarle después al navegador cuanto espacio ocupará la misma. Si tan solo mandamos la url del recurso al navegador, este no va a saber cual es el tamaño de la imagen hasta que no la haya descargado, por lo que vamos a sufrir seguro de cumulative layout shifts. David Walsh publicó hace poco un artículo (curiosamente en tercera persona) sobre como sufría de este problema en su popular blog, cómo lo detectó y cómo lo solucionó. TLDR: Lo solucionó WordPress por el. Aquí no hay Wordpress que valga. En todo caso, YO soy el WordPress. Por lo que necesito almacenar las dimensiones de imagen para poder indicar al navegador desde el lado del servidor cuanto espacio vamos a necesitar para cada una de ellas.
Ya hemos visto como obtener el tamaño de la imagen con identify, ahora necesitamos almacenar esa información en un archivo json que podamos leer desde el servidor al generar la página. Para empezar, vamos a crear un archivo .json con una apertura de llaves en el inicio de nuestro script:
public/images/process-images.sh echo "{" > "$(dirname "$0")/temp_image_sizes.json"
Usando > estamos indicando que queremos sobreescribir el archivo si ya existe.
A continuación, dentro del segundo bucle donde recorremos las imagenes y las redimensionamos, vamos a usar identify tal y como hicimos antes para obtener el ancho y alto del archivo ya redimensionado:
public/images/process-images.sh # Read the height and width of the resized image width=$(identify -format "%w" "${file%.*}.webp") height=$(identify -format "%h" "${file%.*}.webp")
Y vamos a añadir esa información en formato json al archivo que hemos creado:
public/images/process-images.sh # Append the image size to the image_sizes.json file echo "\"${base%.*}\": {\"width\": $width, \"height\": $height}," >> "$(dirname "$0")/temp_image_sizes.json"
Con ${base%.*} eliminamos la extensión del nombre del archivo y lo usamos como clave en el objeto json. A continuación, añadimos el ancho y el alto de la imagen al archivo que hemos creado usando >> en lugar de >, de modo que en lugar de sobrescribir, añadimos una nueva linea.
Una vez fuera del bucle, tenemos que tener en cuenta que el formato json no admite coma de cola: No podemos añadir una coma al final del último elemento de un objeto. Por lo que vamos a eliminar la coma de la última linea con sed:
public/images/process-images.sh sed -i '$ s/,$//' "$(dirname "$0")/temp_image_sizes.json"
Y finalmente cerramos el objeto JSON con una llave de cierre, copiamos su contenido a un archivo definitivo y eliminamos el archivo temporal:
public/images/process-images.sh echo "}" >> "$(dirname "$0")/temp_image_sizes.json" cat "$(dirname "$0")/temp_image_sizes.json" > "$(dirname "$0")/image_sizes.json" rm "$(dirname "$0")/temp_image_sizes.json"pnpm run dev
He usado un archivo temporal por un motivo muy sencillo: Webpack va a estar escuchando cambios en el archivo JSON definitivo y a recargar la página cada vez que los encuentre. La idea es escribir cada linea del JSON conforme vayamos analizando imagen por imagen. Si escribiésemos directamente en el JSON que usamos al generar la web, Webpack detectaría un cambio en un archivo importado y regeneraría con un archivo JSON incompleto (Sin llave de cierre, por lo que fallaría el parseo como JSON), rompiendo el render de la página. Todo ello tantas veces como imágenes tengamos, cada vez que corriese el script. En resumen: Que añadir una imagen nueva al repositorio rompería el servidor de desarrollo.
Por ese motivo utilizo un JSON temporal y, solo cuando está completo, copio su contenido al definitivo, asegurando que Webpack siempre léa un JSON bien formado :thumbsup: Si te preguntas por qué el temporal no rompe el servidor, ningún archivo de la aplicación importa ese temporal, por lo que para Webpack ese archivo no existe.
El script
Y así queda nuestro script terminado:
public/images/process-images.sh #!/bin/sh rm -f "$(dirname "$0")"/*.Identifier # Clean up a file name image_sizes.json echo "{" > "$(dirname "$0")/temp_image_sizes.json" # Loop through all files in the current directory for file in $(find "$(dirname "$0")" -type f ! -name "*.webp" ! -name "*.sh" ! -name "*.json") do # Use cwebp to convert the file to webp format cwebp -q 80 "$file" -o "${file%.*}.webp" # Delete the original file rm "$file" done # Loop through all webp files in the current directory for file in "$(dirname "$0")"/*.webp do width=$(identify -format "%w" "${file%.*}.webp") # If the width is larger than 700px, resize the image if [ $width -gt 700 ] then mogrify -resize 700x "${file%.*}.webp" fi base=$(basename "$file") # Read the height and width of the resized image width=$(identify -format "%w" "${file%.*}.webp") height=$(identify -format "%h" "${file%.*}.webp") # Append the image size to the image_sizes.json file echo "\"${base%.*}\": {\"width\": $width, \"height\": $height}," >> "$(dirname "$0")/temp_image_sizes.json" # Create a placeholder image placeholderPath=$(dirname "$0")/placeholder/${base} if [ ! -f "$placeholderPath" ]; then echo "Creating placeholder for $file" convert "${file%.*}.webp" -blur 0x8 -quality 10 -resize 10x "$placeholderPath" fi done # Remove the last comma from the image_sizes.json file and close the JSON object sed -i '$ s/,$//' "$(dirname "$0")/temp_image_sizes.json" echo "}" >> "$(dirname "$0")/temp_image_sizes.json" cat "$(dirname "$0")/temp_image_sizes.json" > "$(dirname "$0")/image_sizes.json" rm "$(dirname "$0")/temp_image_sizes.json"pnpm run dev
Da un gusto tremendo verlo funcionar, modificando y creando imágenes al vuelo, convirtiendo una tarea tediosa en unos pocos milisegundos de computación. Si bien conocer cada uno de los comandos requiere de mucha experiencia y la sintaxis de bash es bastante extraña si vienes de un lenguaje inspirado en C (como lo es javascript), puedes valerte de una IA para ayudarte a desarrollar este tipo de utilidades.
En mi caso para crear el script simplemente he ido pidiéndole a Copilot lo que necesitaba hacer en cada momento: Buscar todas las imágenes no .webp, ignorar el propio script, comprobar el ancho, etc. Y el me iba dando el código en bash. El resultado no es precisamente el que hubiese escrito un ingeniero de sistemas, pero eso no es razón para no aprovechar las posibilidades de tu maquina. Si como a mí el scripting de shell siempre te ha resultado esquivo, te recomiendo que le des una oportunidad a esta u otra IA que te ayude a ponerte en marcha. Con un poco ensayo y error puedes crear scripts para automatizar tareas pesadas, guardarlos en tu carpeta /usr/local/bin y extender muy fácilmente tu sistema Unix para que haga exactamente lo que necesitas.
Otra opción es crear un script con Typescript y ejecutarlo con ts-node. Esto te permite tener un script más legible (para un desarrollador web al menos) y con la gran ventaja de poder usar import para usar librerías que uses en tu proyecto. Esto es muy util por ejemplo para realizar migraciones de base de datos. En una entrada futura te enseñaré como hacerlo.
Optimizando las imágenes en Next.js
La segunda parte de esta entrada la dedicaremos a usar apropiadamente las herramientas que Next nos provee en relación a las imágenes. Hasta ahora he estado esquivando el componente Image puesto que requiere especificar el tamaño de la imagen y ¿Quien tiene tiempo de mantener un trabajo a tiempo completo, mantener un blog y medir las imágenes a la vez?
Pero ahora que hemos automatizado el proceso, vamos a ver como podemos hacer uso de este componente para mostrar nuestras imágenes con lazy loading, placeholders y el tamaño correcto antes y después de la carga evitando así el temido cumulative layout shift.
En nuestro archivo mdx-content.tsx es donde especificamos cómo transformamos el contenido markdown en elementos html, definiendo componentes. Para las imágenes veníamos haciendo esto:
components/mdx-content.tsx const mdxComponents = { ... img: (props: any) => <img className="w-auto mb-1 m-auto" title={props.alt} alt={props.alt} src={props.src} />, ... }
Cuando definimos una imagen en markdown, lo hacemos de la siguiente manera:

En las props recibimos Texto alternativo como props.alt y /images/nombre-de-la-imagen.webp como props.src. Vamos a sustituir el componente img por el componente Image de Next:
components/mdx-content.tsx img: (props: any) => <Image className="w-auto mb-1 m-auto" alt={props.alt} src={props.src} />,
Simplificando al máximo la definición del src
Para facilitar el uso de imágenes y dado que todas se almacenan en la misma carpeta, vamos a asumir que la ruta solo especifica el nombre de la imagen, sin extensión ni ruta, y vamos a componer nosotros mismos la ruta del recurso:
components/mdx-content.tsx img: (props: any) => <Image className="w-auto mb-1 m-auto" alt={props.alt} src={`/images/${props.src}.webp`} />,
De este modo, mientras escribo el post no tengo que añadir ni la carpeta ni la extensión, solo el nombre de la imagen.
Importante: Este cambio me va a requerir refactorizar TODOS los posts. Por suerte para mí, no tengo muchos 😂.
Especificar las dimensiones
Como src ahora es solo el nombre del archivo, coincide con la clave del objeto json que creamos en el script. Por lo que podemos usar esa información para obtener el tamaño de la imagen y pasárselo al componente Image:
components/mdx-content.tsx import imageSizes from 'public/images/image_sizes.json' ... img: (props: any) => { const { width, height } = imageSizes[props.src as keyof typeof imageSizes] return <Image className="w-auto mb-1 m-auto" alt={props.alt} src={`/images/${props.src}.webp`} width={width} height={height} /> },
keyof typeof nos permite indicarle a Typescript que esté tranquilo, que src es una clave existente en el objeto imageSizes. De este modo estamos trasladando el error al tiempo de ejecución, lo cual no es necesariamente una buena práctica. Pero en este caso específico se justifica por el hecho de que si la clave no existe es porque la hemos escrito mál. Y dado que este es un componente que se ejecuta en el servidor, el tiempo de ejecución es, de hecho, también el tiempo de compilación. Si usamos una clave nó valida, esa linea romperá con una excepción, por lo que no corremos riesgo de mandar imágenes inexistentes al navegador.
De hecho, con esto hemos mejorado nuestro flujo de trabajo: Si una imagen no existe, el script de
buildva a romper y con ello impedirá que una versión rota de la página se despliegue.
Lazy loading
Vamos a indicarle a Next que no queremos mostrar la imagen hasta que no esté cerca de entrar en el viewport. Con esto evitamos descargar todas las imágenes al principio y solo lo hacemos cuando estamos cerca de mostrarlas. Para ello, vamos a añadir la propiedad loading="lazy" al componente Image:
components/mdx-content.tsx img: (props: any) => { const { width, height } = imageSizes[props.src as keyof typeof imageSizes] return <Image className="w-auto mb-1 m-auto" alt={props.alt} src={`/images/${props.src}.webp`} width={width} height={height} loading="lazy" /> },
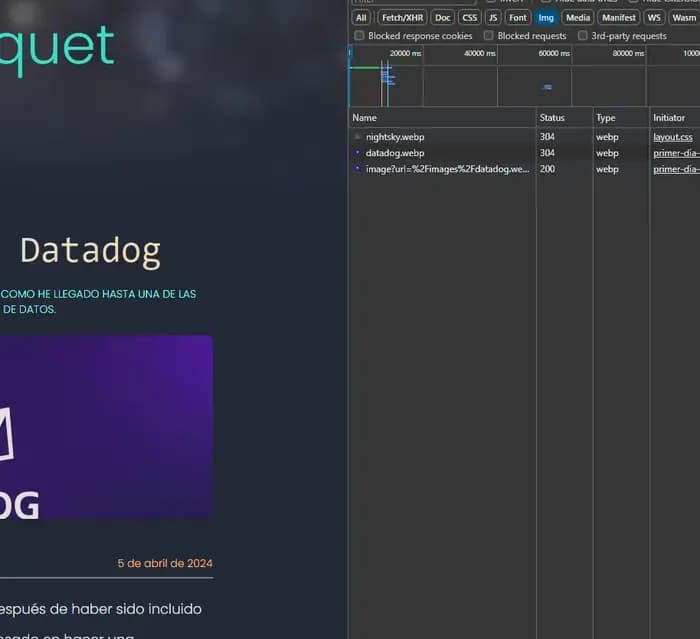
Puedes ir a un post con muchas imágenes (Por ejemplo este), abrir el inspector de elementos, pestaña network, filtrar por imágenes: Podrás ver cómo las imagenes solo se van descargando conforme vas haciendo scroll y te acercas a que sean visibles:
Placeholder
A continuación vamos a añadir el placeholder. Para ello, vamos a setear la propiedad placeholder a blur en el componente Image, y vamos especificar la ruta a la imagen que generamos anteriormente:
components/mdx-content.tsx return <Image className="mb-1 m-auto" alt={props.alt} src={`/images/${props.src}.webp`} width={width} height={height} loading='lazy' placeholder='blur' blurDataURL={`/images/placeholder/${props.src}.webp`} />
Como hemos especificado height y width, si bien el placeholder tiene solo 10px de ancho, en el navegador se estirará a las dimensiones indicadas. Evitamos así el cumulative layout shift y mostramos efectivamente un imagen en baja resolución mientras se carga la definitiva.
Pies de foto
Por último, voy a solucionar el tema de los pies de foto. Hasta ahora he venido poniendo un texto en cursiva debajo de la imagen. A parte de no quedar muy allá:

Tiene el problema de que no es accesible. Las personas con problemas de visión no van a poder saber que ahí hay un pie de foto. Por lo que vamos a añadir un figcaption a la imagen para dejar claro desde el punto de vista semántico, y no solo visual, que se trata de un pié de foto:
components/mdx-content.tsx return <figure> <Image ... /> <figcaption className='text-xs text-center text-slate-300'>{props.alt}</figcaption> </figure> }
Comparando lo anterior con lo nuevo:

Luce mejor, pero tenemos dos problemas:
-
Como se ve en el ejemplo, no siempre el alt y el pie de foto coinciden
-
Si lo dejo así, voy a asumir que todas las imagenes van a tener pie de foto, y esto no es así en este blog. Por lo que me obligaría a actualizar todos los posts. De nuevo, no son muchos pero no me apetece revisarlos todos.
Por lo que vamos a implementar un sistema que permita añadir el pie de foto desde el markdown sin demasiada complicación. Las reglas serian:
-
Si nos encontramos una
@en el texto alternativo, la foto tendrá pie de foto. De este modo nos aseguramos de no romper la compatibilidad con los posts anteriores. -
Si nos encontramos la
@, el texto que la precede será elalty el que vaya detrás de ella será el pie de foto. -
Si nos encontramos la
@pero no hay texto detrás, elalty el pie de foto serán el mismo.
Modifico una vez más el componente para añadir la lógica descrita:
components/mdx-content.tsx img: (props: any) => { const { width, height } = imageSizes[props.src as keyof typeof imageSizes] const [alt, caption] = props.alt.split('@') const hasCaption = caption !== undefined return <figure> <Image ... /> {hasCaption ? <figcaption className='text-xs text-center text-slate-300'>{ caption || alt }</figcaption> : null } </figure> }
Y ahora puedo modificar el markdown de esto:
 _Elige uno y arranca tu carrera como web-developer_
A esto:

Y disfrutar de esos lindos y semánticos pies de foto:

OJO! remark por defecto envuelve todos los elementos en un párrafo, así que con este cambio estamos metiendo un figure dentro de p, lo cual es semánticamente incorrecto y nos da errores de hydration al mandar la página al cliente.
He tenido que echar un par de horas investigando el asunto y no quiero explicarlo aquí ya que el post se ha vuelto ya demasiado largo. TLDR: Puedes usar un plugin de Remark para evitar este comportamiento con imagenes, lo cual limpia el problema de raíz. Tengo este commit en el que implemento esta solución y actualizo next-mdx-remote para usar RSC, aprovechando que he migrado a Next 14.
Por la misma razón, tampoco me he extendido en como he utilizado chokidar para monitorizar la carpeta images y correr el script automáticamente cada vez que añado una imagen. O como he actualizado el linter para facilitarme el trabajo. Si tienes interés, puedes checkear la PR en Github y ver todo lo que se ha quedado fuera de este post.
Conclusión
Hemos aprendido a automatizar una tarea muy tediosa como es preparar las imágenes para usarlas en la web. Hemos simplificado la interfaz en MDX para que usarlas sea los más sencillo posible. Hemos mejorado la experiencia de usuario con lazy loading y placeholders. Y finalmente hemos mejorado la accesibilidad de las imágenes añadiendo pies de foto semánticos. Todo ello a la vez que hemos mejorado el SEO y los Core Web Vitals al mejorar el tamaño de las imagenes y el layout shift y hemos hecho la páginas más accesible para lectores de pantalla.
En el camino hemos aprendido a usar algunas herramientas de terminal muy interesantes y hemos mejorado nuestro entendimiento de Next.
Si has llegado hasta aquí después de semejante ladrillo, te doy las gracias por tu tiempo y espero que te hayas llevado algo de provecho. Llevo más de un més trabajando en esta entrada y te prometo que es la última vez que me extiendo tanto. ¡Nos vemos en la próxima entrada!